С контактами (организациями и людьми) разобрались - там хоть и навороченно, но вопросов пока нет концептуальных.
Переходим к Задачам.
Экспериментировать будем на HelpDesk. За пример возьмем opentodo и bugzilla - с доработкой напильником под себя.
(Следующей кошкой можно взять классику - Заявка/Счет/Оплата/Доверка/Накладная|Акт+СФ/Оприход. Тут уже интереснее - масса ветвлений и неожиданных поворотов - зато всё определено (а на этой базе можно сделать данный документооборот - с формами, но без бухучета... Кстати - идея! :-)).
Общие принципы:
* все объекты (в т.ч. задачи) наследуют одного предка;
* все специфичные задачи наследуют общий класс Задача - с доработкой по месту;
прохождение задачей своего жизненного пути - это цепь задач, только одна из которых (последняя в цпочке) может быть активной. Остальные уходят в архив - для истории;
* Задача может быть только открытой и закрытой;
* Закрыться задача может только успешно - или родив следующую задачу;
Задача может включать другие задачи, только когда все подзадачи завершены (условия и/или - потом);
* Задачу можно заблокировать успешным выполнением другой задачи (то, что в bugzilla назвается блокирующим багом). Это - не подзадача, а совсем из другого потока.
Итак - пора рисовать классы (на пальцах):
GwObjectПредок всех остальных классов. Gw - от GroupWare. Здесь прошиты возможности наследования, группировки и ассоциаций - всё по-взрослому. Все поля (кроме type) - необязательные:
* type:GwOType - тип наследника (расписыват не буду - просто enum); Обязательно прописывается наследниками.
* ancestor:GwObject - предок - объект, с которого тянутся поля, которые в данном объекте не прописаны (пример: девушку угораздило выйти замуж; тогда всё, кроме фамилии, она может наследовать от своей предыдуще жизни);
* group:GwObjects[] - массив подчиненных объектов. Хотя в первой версии лучше сделать поле master:GwObject - объект, которому подчинен данный. В последнем случае 1 объект может входить только в одну группу, но на безрыбье пока хватит.
* links:GwObjects[] - связи, просто связи. Связи образуют некие группы, один объект может участвовать в нескольких группах связей. Реализация тривиальна, расписывать не буду.
Методы:
* delete() - здесь объект должен поприбивать всех подчиненных (это будет сделано автоматом) и связи (аналогично).
* addson() - (решил сюда перенести, раз уж группы - здесь) - добавить подобъект (того же типа (?)).
* delson() - хез, может надо...
TaskЗадача в самом общем виде. В принципе, её можно сразу и сажать в некий tasklist. Все поля (почти) тоже необязательны.
* subtype:TaskType - здесь, например, HdTask (задача HelpDesk'а) указывает свой подтип.
* author - понятно
* assignee - понятно
* created - обязательно, автомат
* deadline - понятно
* subject - обязательно
* description - понятно
* completed:bool - True - задача завершена
* result:enum(Null/ok/forward) - если задача завершена, то поле должно быть установлено - в ok, если всё чики, или в forward - если неуспешно и управление перешло следующей задаче. Вариант #2 - этого поля нет, а поле prev заменить на необязательное next - так будет лучше с т.з. неизбыточности даннных.
* prev:Task - какой задаче перешло управление по завершению данной. Обе задачи должны иметь один subtype (?). Это поле - реализация последовательности задач - об чем, собсно, и гениальность идеи - реализация бизнес-процессов как групп/последовательностей задач. По существу - однонаправленный список (хотя, может, лучше сделать двунаправленный?..)
Методы:
* delete() - здесь, ко всему прочему, надо "выкусить" себя из последовательности.
* complete() - завершить успешно. Мы не можем завершить задачу, пока не завершены успешно все подзадачи.
* forward() - завершить эту задачу, родить новую, передать ей всё, что надо - и сообщить папе (master'у группы), что мы уже не играем, мы в домике (архиве) - а за нас играет следующая задача (вот её окончания и надо ждать).
HdTaskСобсно, задача для HelpDesk. Все поля - необязательные.
* project:Project - ну или там тема, категория... Для фильтра.
* state:enum - состояние текущей задачи - в соответствии с диаграммой состояний.
* comments:txt[] - каменты.
* files:File[] - файлы.
Все поля можно указать только в главной задаче, в подзадачах - или не указывать совсем, или наследовать - кроме state (пока не решил).
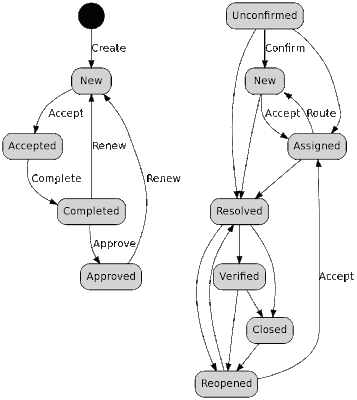
Диаграммы состояний opentodo и bugzilla:
В принципе, если выкинуть справа состояние Unconfirmed (которое нужно только в public-трекерах), то диаграммы очень похожи. Ну, разве что, слева - более упрощена. Кроме того, добавим action "поцепить зависимость от другой задачи" (есть прецеденты).
Вот теперь будет use cases на пальцах.
* Юзверь создает задачу. Создается HdTask и сразу же - его первая (если не будет аварии - единственная) подзадача того же типа HdTask. Мегазадача будет ждать, пока текущая подзадача не завершится успешно. Пусть юзверь не назначил исполнителя (блондинко, куле...), подзадача будет со статусом Unassigned.
* Сисодмин видит список Unassigned-задач, назначает исполнителя. Этим он завершает задачу-сына, но не успешно, а forward: эта подзадача закрывается, открывается новая, в старой прописывается поле next, мастер-задаче вместо первой подзадачи подсовывается новая, старая уже не играет и уходит в историю. Теперь мастер-задача ждет окончания второй подзадачи. Новая задача имеет статус Assigned. Можно браться за работу.
* Исполнитель может обнаружить, что одна задача требует массу телодвижений. Не бидэ - жмем педаль "Подзадачи" - и текущая подзадача (2-го уровня) рождает несколько подзадач (уже третьего) - и будет нежно ждать успешного завершения всех из них.
* Или же исполнитель обнаружил, что ему сказали налить ведро воды, а он вчера сказал секретутке купить ведро (оракул потому что). Тогда он может повесить свою задачу в DenendsOn задаче, которую дали ему. Это разные задачи и не из одной группы - но факт имеет место быть. Тут пока плавает, на первом этапе можно похерить (возможно, лучше сделать вхождение объекта во много групп).
* Ну, пуст исполнитель тупо выполнил задачу Assigned. Жмем педаль, задача закрывается, пойвляется новая - с состоянием Resolved (Master-задаче статус не даем - она тупо ждет завершения всех подзадач - это для тех мастер задач, которые запускают сразу несколько подзадач).
* Автор проверят результат, жмет "Одобряю". Состояние новой подзадачи становится - Verified.
* Исполнитель жмет "Close". Подзадача завершается успешно. Можно вручную или или же автоматом закрыть и основную задачу. Тема закрыта.
Слайды